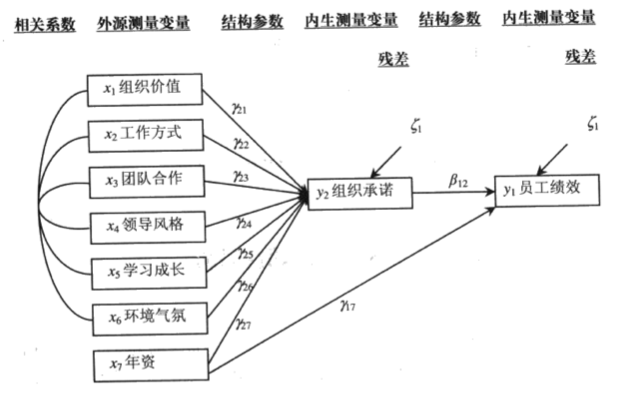
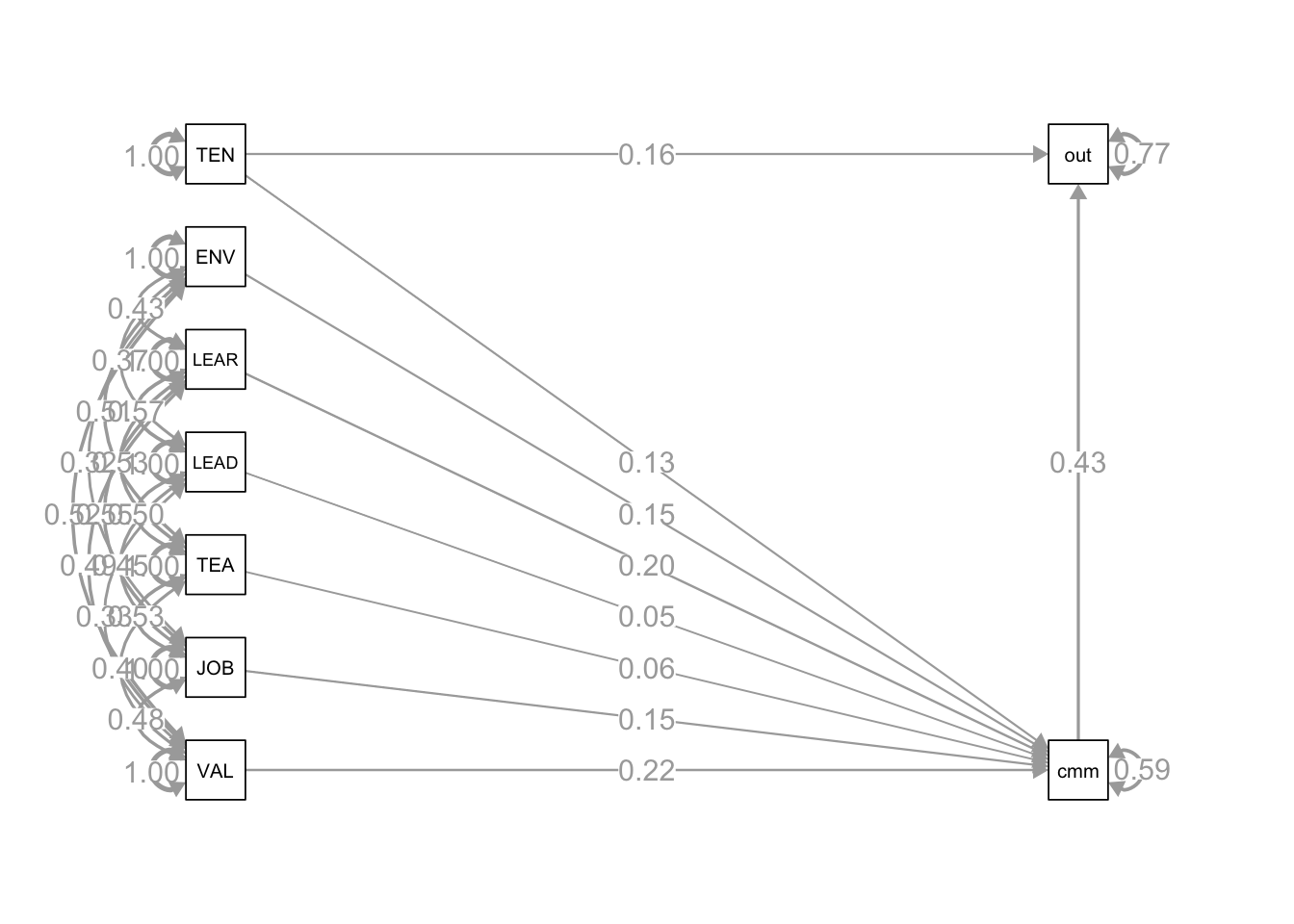
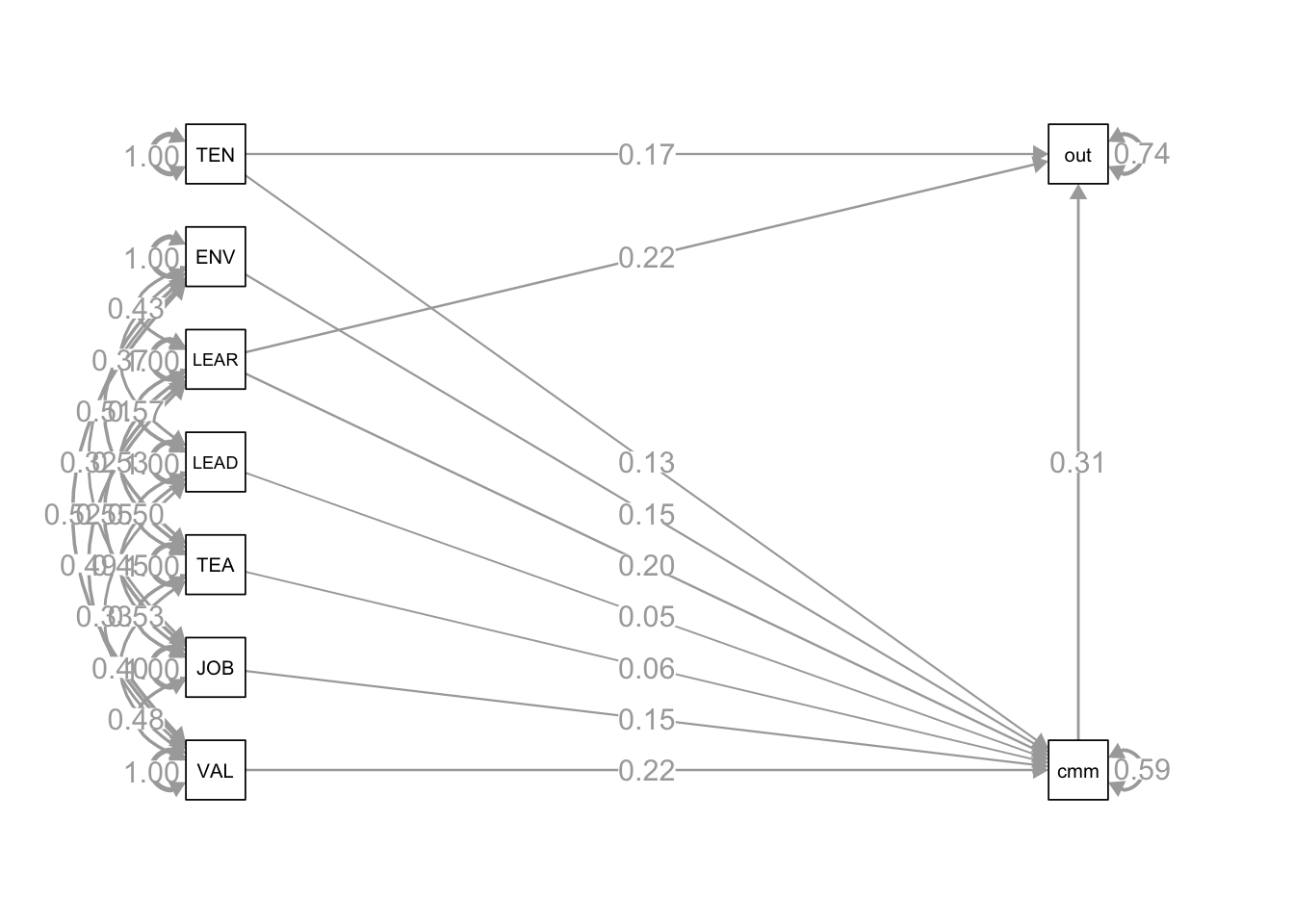
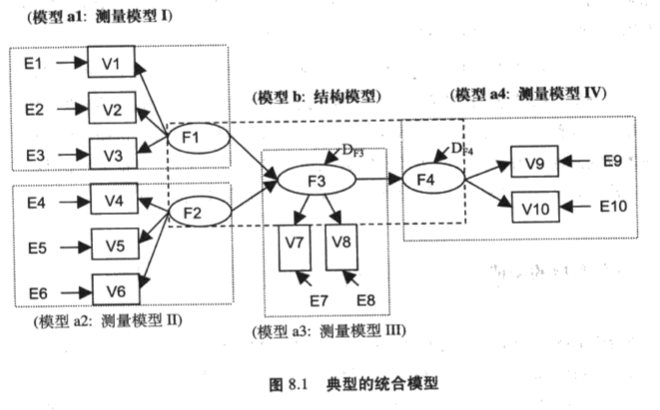
调节变量(Z):企业技术创新能力(Technological Innovation in Firms)。
解释:具有高技术创新能力的企业能够更好地适应和满足严格的环境政策要求。
效果:
高创新能力:政策严格性对治理成效有更大影响。
低创新能力:政策严格性可能导致高成本而无法显著改善污染。
可视化调节效应
调节效应通常用交互图(Interaction Plot)展示。
将( X ) 和 ( Y ) 的关系在不同 ( Z ) 水平下的表现。
不同 ( Z ) 水平会呈现不同的斜率或曲线。
调节效应分析示例
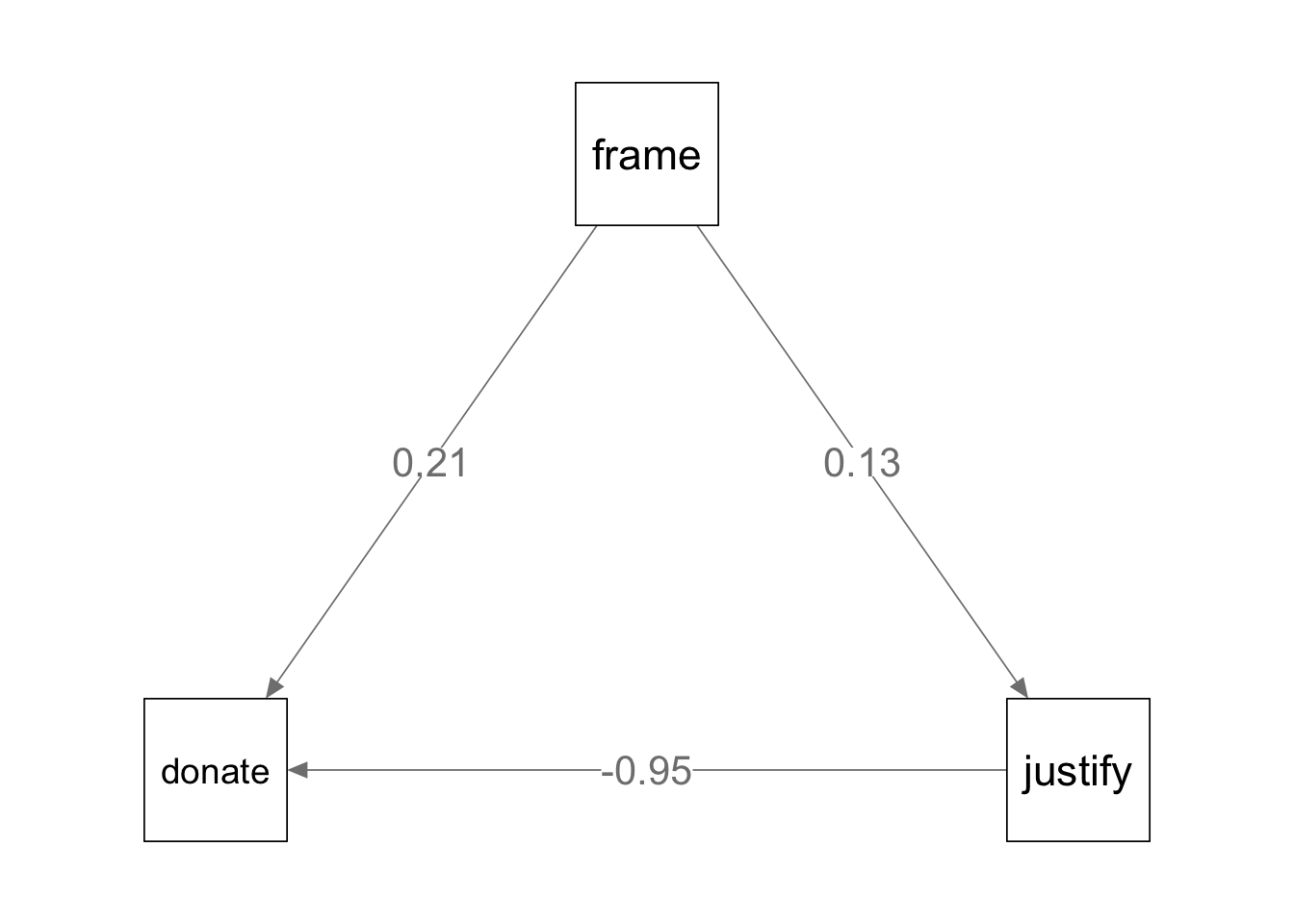
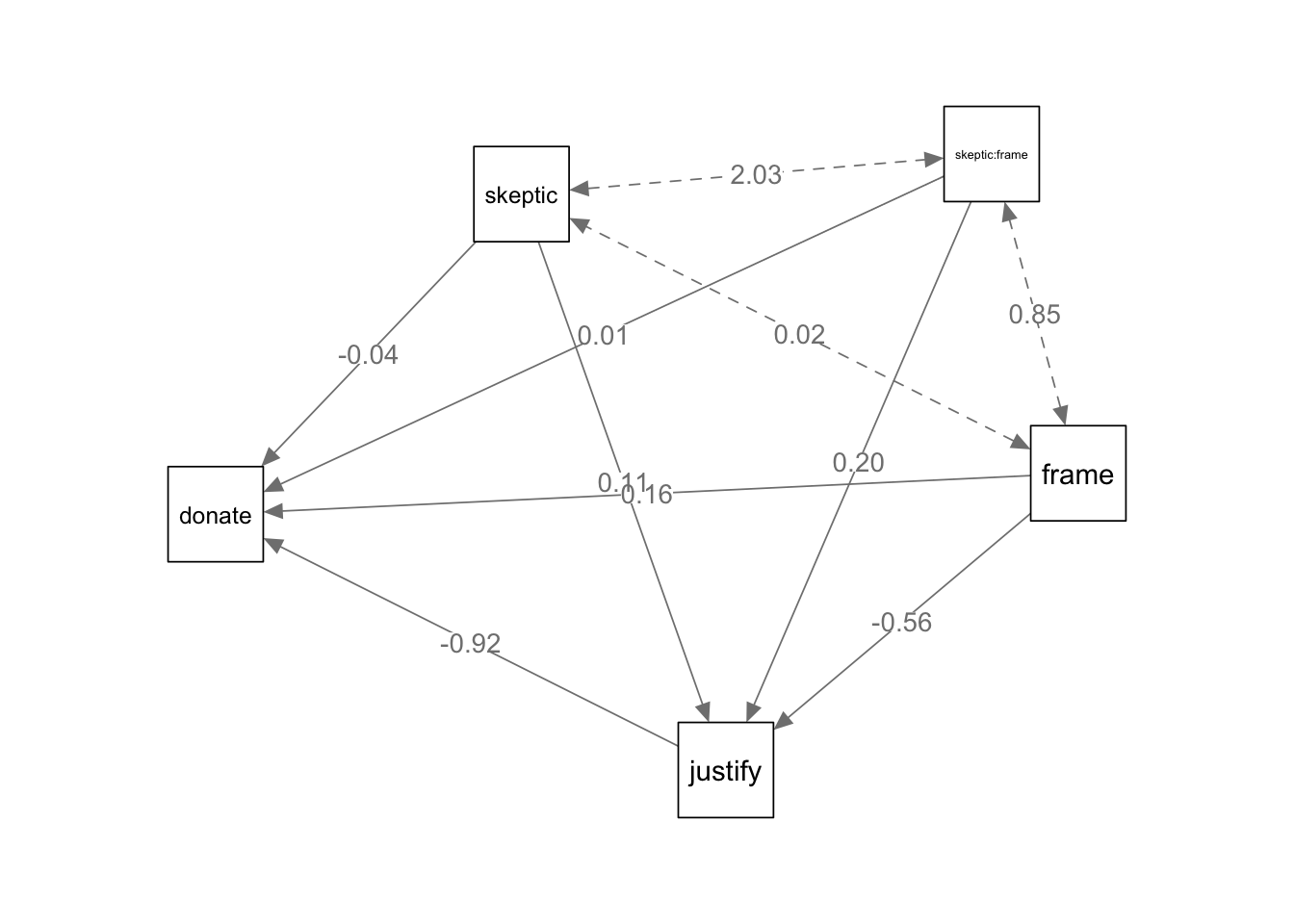
一项关于气候变化与灾害Chapman and Lickel 2015的研究中,研究者向211名实验参与者讲述非洲发生干旱造成人道主义危机,告诉其中一半的参与者气候变化是造成干旱的原因,另一半参与者未被告知任何关于干旱的原因。接着通过一系列问题让实验参与者评价拒绝援助的正当性,以及了解他们对气候变化的怀疑程度。最后了解参与者捐款的意愿。 实验的目的是了解框架(frame),即是否告知干旱是由于气候变化产生的,对捐助意愿(donate)的影响数据。
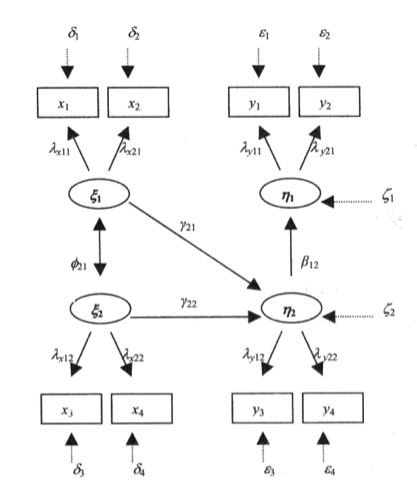
条件过程模型(Conditional Process Model)是一个综合框架,用于同时分析中介效应(Mediation Effect)和调节效应(Moderation Effect)。它探讨自变量通过中介变量影响因变量的机制,同时考虑调节变量如何影响这一机制的强度或方向。条件过程模型是一种强大的分析工具,能够揭示复杂的变量关系,为研究者提供深入的理论解释和实践指导。
条件过程模型的基础
条件过程模型结合了中介效应和调节效应,回答以下关键问题:
机制问题:自变量如何通过中介变量间接影响因变量?(中介效应)
情境问题:这种中介效应在什么情况下更强或更弱?(调节效应)
公式化表示为: [ Y = b_1 M + b_2 X + b_3 W + b_4 (M W) + ] 其中: