在公共管理与公共政策研究中,分析对象往往天然嵌入空间:城市、县区、社区、街区、流域、区域网络等。公共服务供给、环境污染、财政支出、社会风险、政策扩散等问题,都表现出明显的空间相关性(spatial dependence)与空间溢出(spillover effects)。
传统计量方法通常假定观测单元相互独立(i.i.d.),这一假设在空间情境下往往被系统性违反,从而导致估计偏误或推断失效。
1 空间数据与探索性空间数据分析
1.1 空间数据与 Shapefile
空间计量分析通常结合:
属性数据 (如:人口、财政支出、污染排放)
空间几何数据 (点、线、面)
Shapefile 是最常见的空间矢量数据格式,由 .shp、.shx、.dbf 等文件组成。
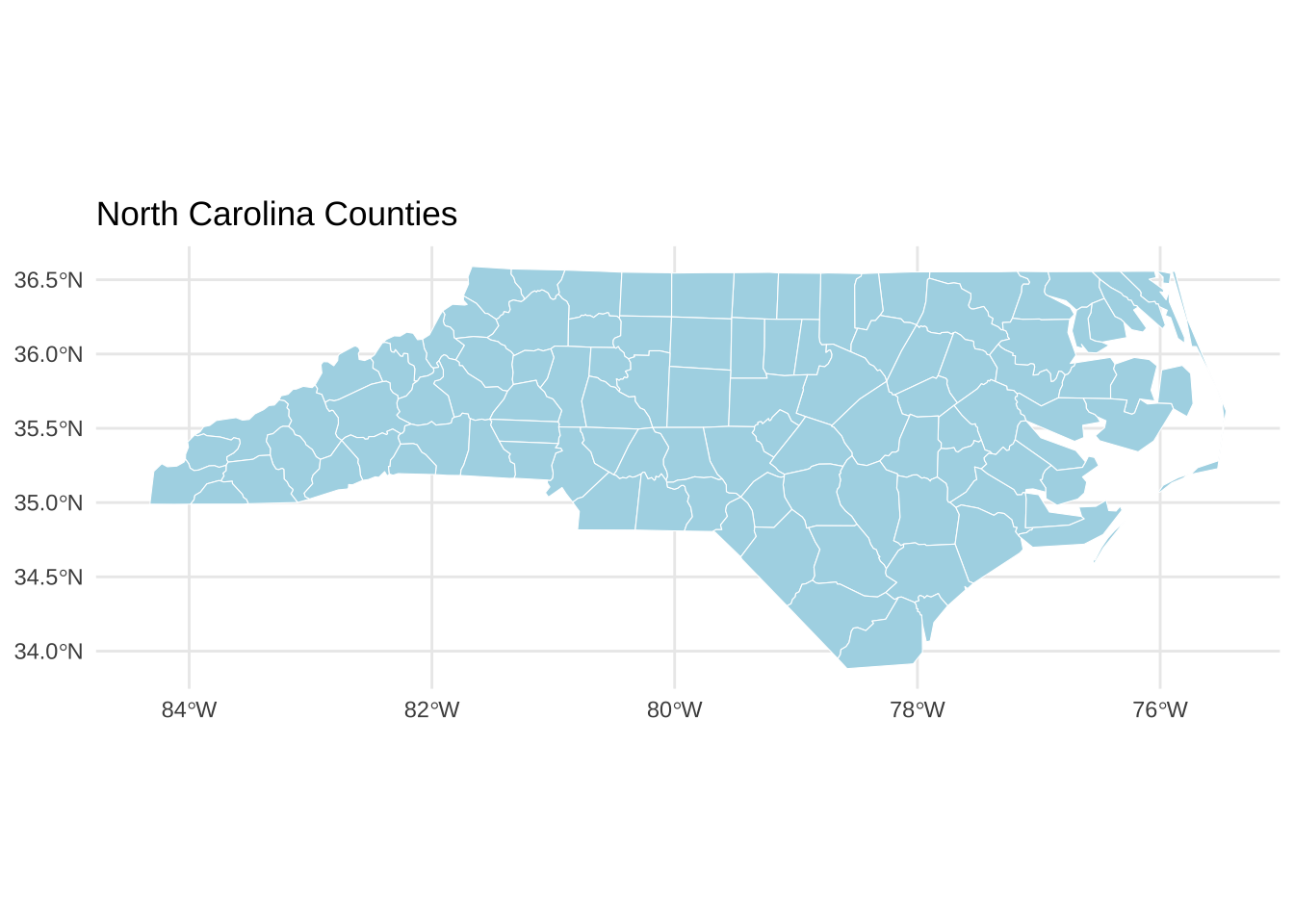
library (sf) library (ggplot2)<- st_read (system.file ("shape/nc.shp" , package= "sf" ))
Reading layer `nc' from data source
`/Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/library/sf/shape/nc.shp'
using driver `ESRI Shapefile'
Simple feature collection with 100 features and 14 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -84.32385 ymin: 33.88199 xmax: -75.45698 ymax: 36.58965
Geodetic CRS: NAD27
<- st_transform (nc, 4326 )ggplot (nc) + geom_sf (fill = "lightblue" , color = "white" ) + theme_minimal () + labs (title = "North Carolina Counties" )
2.2 空间权重矩阵(W)
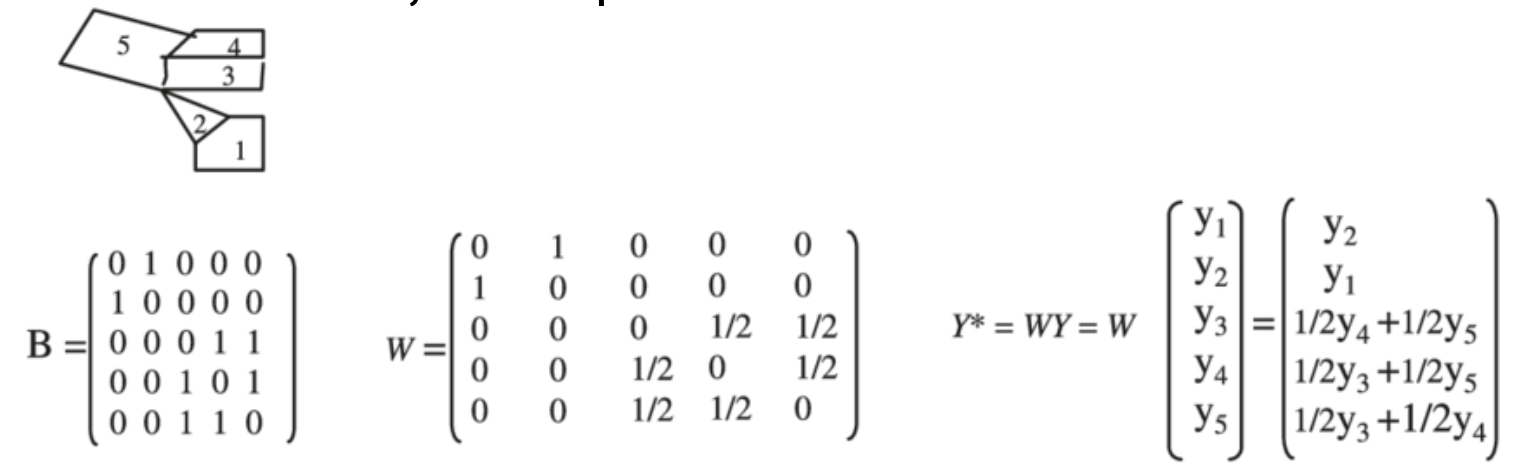
空间计量的核心在于空间权重矩阵 ,用于刻画“谁与谁相关”。
描述空间单位间的结构或连通性
常为n×n稀疏矩阵,行标准化(行和为1)
空间矩阵有不同的构建方式。
2.2.1 连通型矩阵
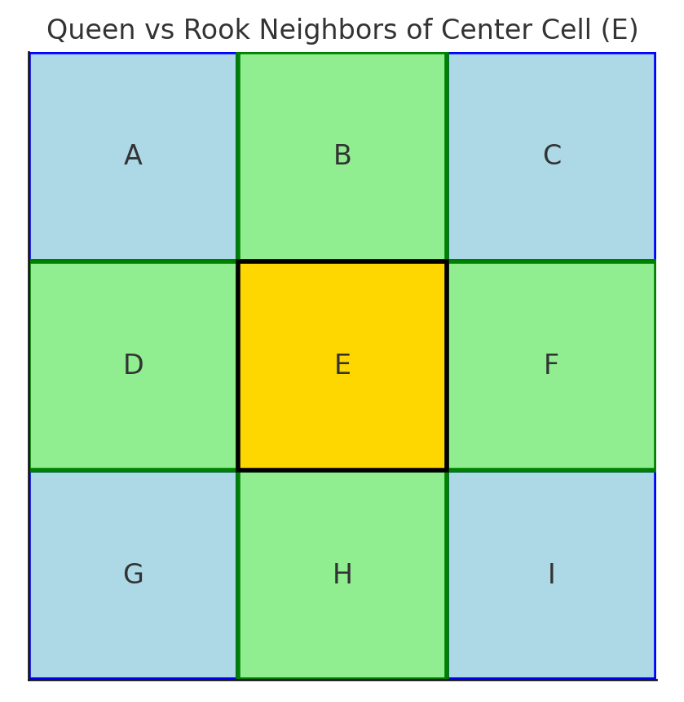
Rook邻接 :共享边界的邻居Queen邻接 :共享边界或角落的邻居示例:中心单元(E)的邻居
Rook:B、D、F、H
Queen:A、B、C、D、F、G、H、I
2.2.2 距离型矩阵:
反距离权重:1/d^2
距离带法:指定范围内为邻居
K近邻:最近的K个单位为邻居
2.2.3 非地理型矩阵:
社交连接:谁与谁在社交网络中互动
经济相似性:哪些公司属于同一行业或具有相似财务特征
功能关系:组织内哪些部门在项目中合作
共享属性:哪些个体具有相似的年龄、收入或政治观点
2.2.4 如何选择 W?
W矩阵的设定具有一定的主观性
不设W(即设为0)意味着假设空间独立,反而更强
不同W可能导致参数估计差异(尤其在早期文献中)
实证研究会有许多不同的矩阵设定,通过敏感性分析消除疑虑
2 空间计量模型的理论基础
2.1 理论基础
地理学第一定律 (Tobler,1970):“一切事物都是相关的,但近的事物比远的更相关。” 溢出效应 :一个地区的结果受邻近地区影响战略相互依赖 :个体根据邻居行为反应(如地方政府在财政、环保、公共服务领域存在策略互动)遗漏变量偏差 :空间上相关但不可观测的制度或社会因素网络治理结构 :非地理空间(组织、功能、社会网络)同样存在“空间”结构
2.2 空间过程与模型匹配
i.i.d.假设被破坏
空间自相关误差项
SEM
溢出效应
滞后因变量起作用
SAR
战略互动
内生空间依赖
SAR、SDM
遗漏变量
相关误差项
SEM
政策扩散
间接/溢出效应
SDM
2.3 实证动因 - 实际案例
城市经济学:房价、急救响应、污染
公共财政:税收模仿、支出溢出
区域发展:基础设施跨区域影响
流行病学:疾病传播模式
忽略空间效应会低估政策影响或误判显著性水平
2.4 空间滞后
空间滞后是时间序列相关性的空间类比,但更为复杂。
主要区别:
空间滞后是多方向关系,而时间序列相关性是单方向(只能过去影响未来)。
空间滞后会消耗自由度,而时间序列相关性不会。
空间滞后使用预定义的空间权重矩阵(W),而时间序列相关性没有。
空间滞后性可比较不同的W矩阵以获得稳健性结果。
空间异质性??
2.5 何时考虑空间回归?
每个观测值对应一个空间位置或区域
一定要进行探索性空间数据分析以识别空间相关性
2.6 空间(自)相关指标
全局莫兰指数(Global Moran’s I)
为整个研究区域提供一个值
取值范围:-1 到 +1
0 表示完全随机
-1 表示完全分散(负相关,高-低/低-高)
+1 表示完全聚集(正相关,高-高/低-低)
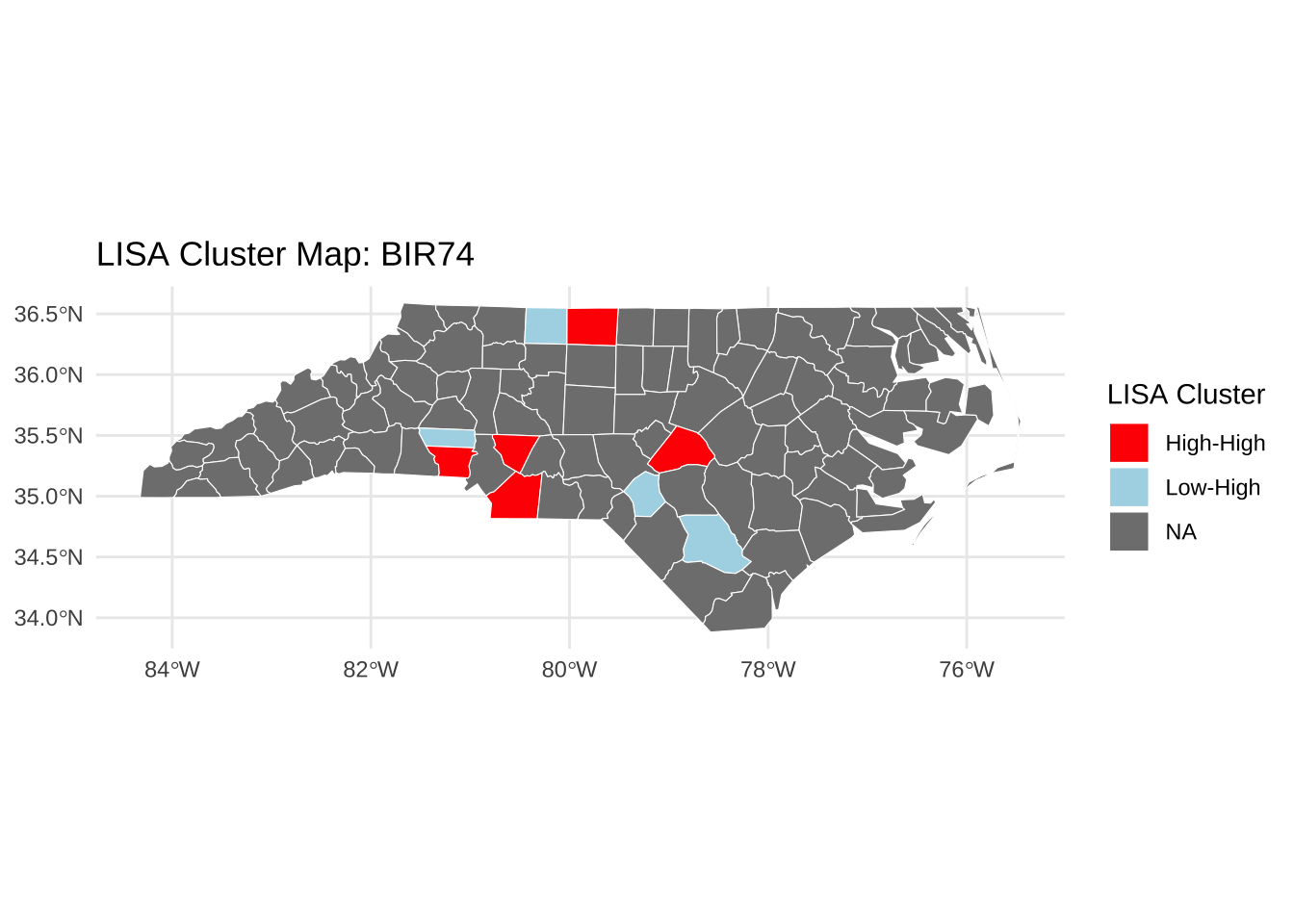
局部空间自相关(LISA(Local Indicators of Spatial Autocorrelation),Anselin, 1995)
为每个空间单位提供一个值
所有观测值的LISA总和与全局空间关联指标成比例
聚集类型:高-高 或 低-低
异常值:高-低 或 低-高
全局与局部统计可扩展到双变量空间相关
双变量全局莫兰指数 :一个单位中的变量是否与邻近单位的另一个变量在全局范围内空间相关双变量局部莫兰指数 :一个单位中的变量是否与邻近单位的另一个变量在局部范围内空间聚集与皮尔逊相关系数不同,不仅考虑数值相关性,还考虑地理接近性
2.7 案例数据
数据集:NC(spData 或 spdep 包)
范围:北卡罗来纳州100个县
变量 :BIR74, BIR79:1974年和1979年的出生数
SID74, SID79:1974年和1979年的婴儿猝死数
NWBIR74, NWBIR79:1974年和1979年非白人母亲的出生数
NAME, FIPS, CNTY_ID:县标识符和名称
来源与原始出版 :
原始研究:Cressie, Noel. (1993). Statistics for Spatial Data . Wiley.
由Luc Anselin等人编译,最初用于空间计量建模
参考文献:Bivand, Roger S., Edzer J. Pebesma, and Virgilio Gómez-Rubio (2008, 2013). Applied Spatial Data Analysis with R .
读取数据与呈现
library (sf)library (spdep)library (ggplot2)library (leaflet)library (spatialreg)library (lmtest)library (stargazer)library (gt)library (dplyr)# 载入shp文件 <- st_read (system.file ("shape/nc.shp" , package= "sf" ))
Reading layer `nc' from data source
`/Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/library/sf/shape/nc.shp'
using driver `ESRI Shapefile'
Simple feature collection with 100 features and 14 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -84.32385 ymin: 33.88199 xmax: -75.45698 ymax: 36.58965
Geodetic CRS: NAD27
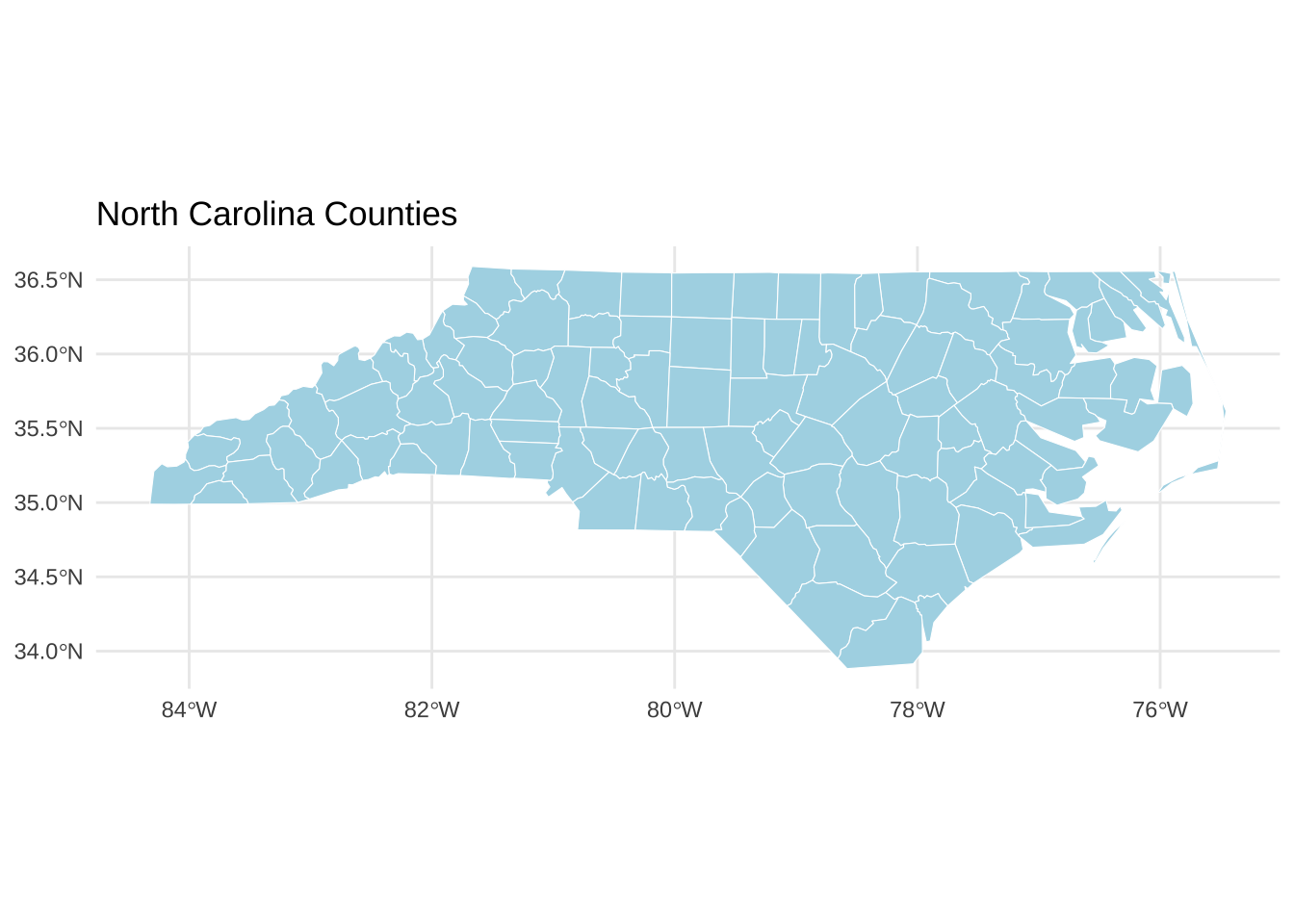
# 将空间数据转换为WGS84经纬度坐标系,便于与其他通用地理数据或工具(如Leaflet、ggplot2等)兼容 <- st_transform (nc, crs = 4326 )# 可视化 ggplot (nc) + geom_sf (fill = "lightblue" , color = "white" ) + theme_minimal () + labs (title = "North Carolina Counties" )# 采用leaflet包创建交互式地图 <- colorNumeric ("YlGnBu" , domain = NULL ) # 可根据需要定义变量 leaflet (nc) %>% addTiles () %>% addPolygons (fillColor = ~ pal (1 ), # 可根据变量选定颜色 fillOpacity = 0.6 ,color = "black" ,weight = 1 ,popup = ~ paste ("ID:" , row.names (nc))
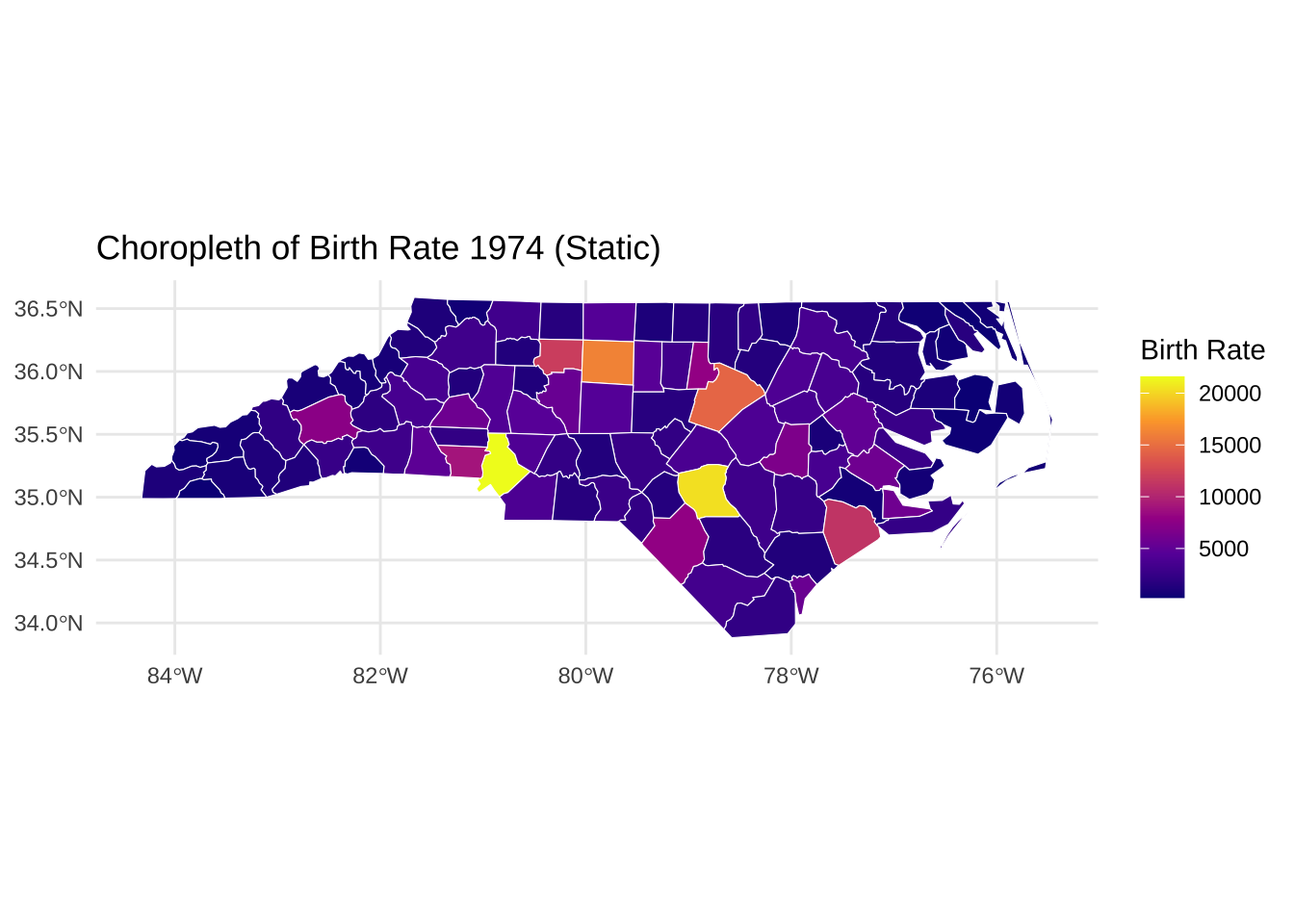
# 采用ggplot2绘制静态地图 ggplot (nc) + geom_sf (aes (fill = BIR74), color = "white" ) + scale_fill_viridis_c (option = "C" , name = "Birth Rate" ) + theme_minimal () + labs (title = "Choropleth of Birth Rate 1974 (Static)" )# 采取leaflet绘制交互式地图 <- colorNumeric (palette = "YlOrBr" , domain = nc$ BIR74)leaflet (nc) %>% addTiles () %>% addPolygons (fillColor = ~ pal (BIR74),fillOpacity = 0.7 ,color = "black" ,weight = 1 ,popup = ~ paste ("Birth Rate:" , BIR74)%>% addLegend ("bottomright" , pal = pal, values = ~ BIR74,title = "Birth Rate" )
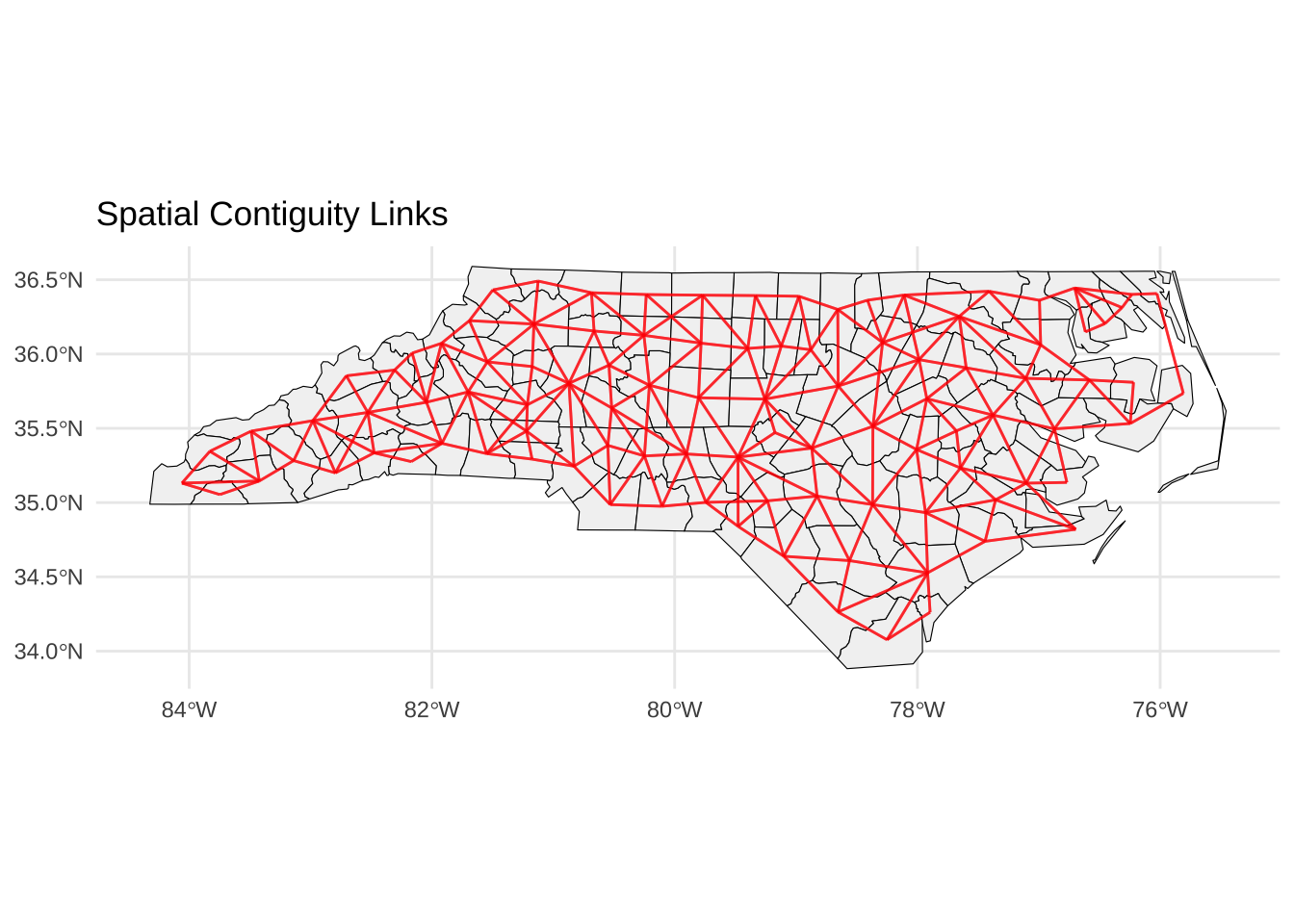
# 创建连通加权矩阵(queen) <- poly2nb (nc) # 从多边形生成邻居列表 <- nb2listw (nb_contig, style = "W" ) # 添加按行标准化的权重 # 可视化连通性 <- st_centroid (st_geometry (nc))<- st_coordinates (centroids) # 获取地理单元的中心点及其坐标 <- nb2lines (nb_contig, coords = coords, as_sf = TRUE )st_crs (nb_lines) <- st_crs (nc) # 将邻居列表转化为空间线条数据框,并附加坐标系 # 呈现邻居连通性 ggplot () + geom_sf (data = nc, fill = "grey95" , color = "black" ) + geom_sf (data = nb_lines, color = "red" , size = 0.5 , alpha = 0.6 ) + theme_minimal () + labs (title = "Spatial Contiguity Links" )
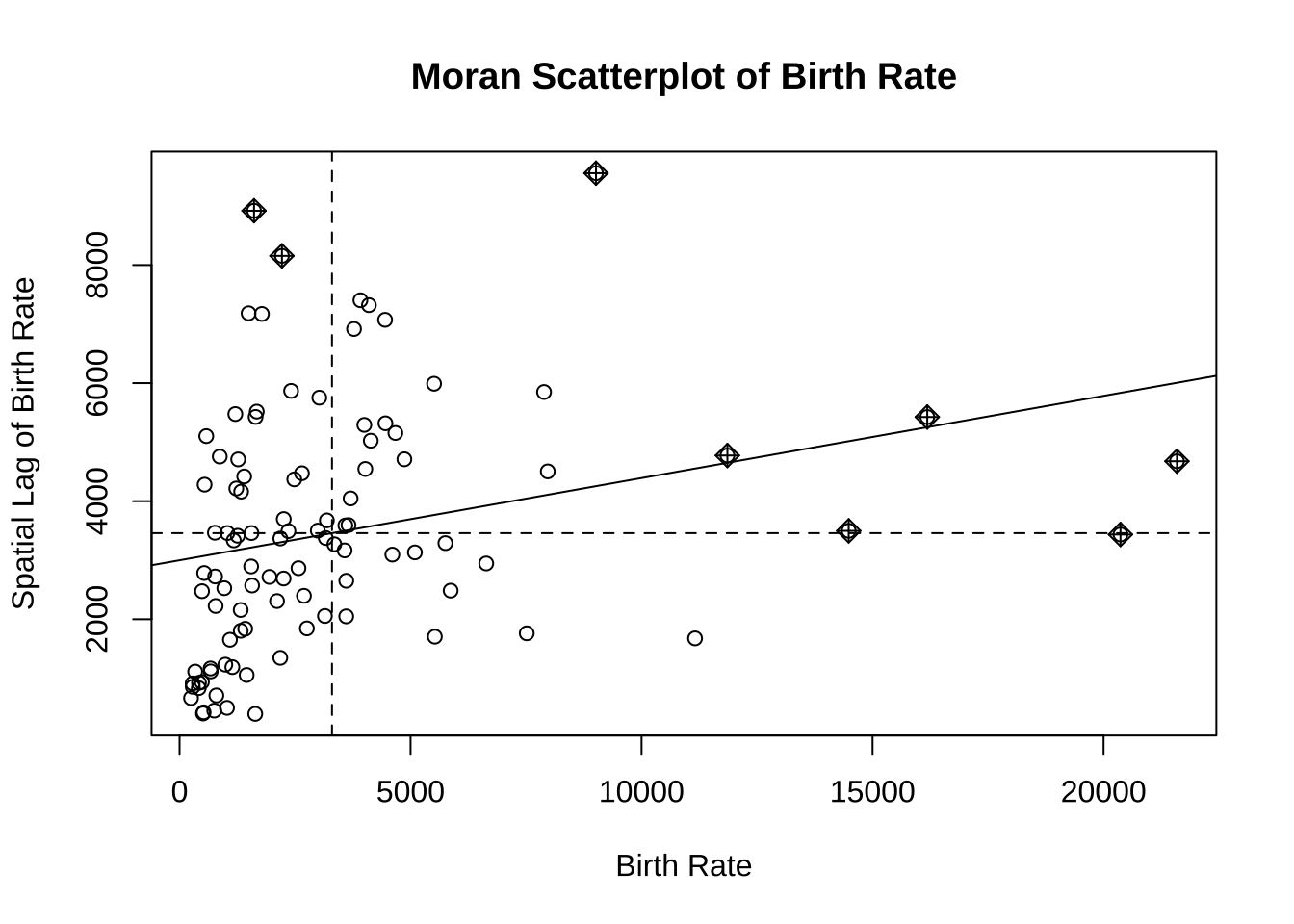
# 莫兰检验和呈现 moran.test (nc$ BIR74, listw = listw_contig)
Moran I test under randomisation
data: nc$BIR74
weights: listw_contig
Moran I statistic standard deviate = 2.4055, p-value = 0.008074
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.139319332 -0.010101010 0.003858258
moran.plot (nc$ BIR74, listw = listw_contig,labels = FALSE , xlab = "Birth Rate" ,ylab = "Spatial Lag of Birth Rate" ,main = "Moran Scatterplot of Birth Rate" )
# 利用空间权重矩阵,获取变量的空间滞后项 $ lag_BIR <- lag.listw (listw_contig, nc$ BIR74)# 基于空间权重,分别计算每个地理单元局部莫兰指数 <- localmoran (nc$ BIR74, listw= listw_contig)# 添加局部莫兰指数的结果,包括指数统计量、标准差、显著性水平 $ Ii <- local_moran[, "Ii" ]$ Z_Ii <- local_moran[, "Z.Ii" ]$ p_Ii <- local_moran[, "Pr(z != E(Ii))" ] # 划分LISA集合的类别 # Global means <- mean (nc$ BIR74, na.rm = TRUE )<- mean (nc$ lag_BIR, na.rm = TRUE )$ cluster <- factor (ifelse (nc$ BIR74 > mean_BIR & nc$ lag_BIR > mean_lag & nc$ p_Ii <= 0.05 , "High-High" ,ifelse (nc$ BIR74 < mean_BIR & nc$ lag_BIR < mean_lag & nc$ p_Ii <= 0.05 , "Low-Low" ,ifelse (nc$ BIR74 > mean_BIR & nc$ lag_BIR < mean_lag & nc$ p_Ii <= 0.05 , "High-Low" ,ifelse (nc$ BIR74 < mean_BIR & nc$ lag_BIR > mean_lag & nc$ p_Ii <= 0.05 , "Low-High" ,"Not Significant" )))),levels = c ("High-High" , "Low-Low" , "High-Low" , "Low-High" , "Not Significant" )# Optional: Make sure 'cluster' is a factor with proper levels $ cluster <- factor (nc$ cluster, levels = c ("High-High" , "Low-Low" , "High-Low" , "Low-High" , "Not significant" ))# Define custom colors for each cluster type <- c ("High-High" = "red" ,"Low-Low" = "blue" ,"High-Low" = "orange" ,"Low-High" = "lightblue" ,"Not significant" = "lightgray" # Plot using ggplot ggplot (nc) + geom_sf (aes (fill = cluster), color = "white" , size = 0.2 ) + scale_fill_manual (values = cluster_colors, name = "LISA Cluster" ) + labs (title = "LISA Cluster Map: BIR74" ) + theme_minimal ()
3 空间计量模型构建
3.1 基本模型形式
空间误差模型(SEM) :\(Y = \alpha + X\beta + \mu, \mu = \rho W\mu + \epsilon\) 空间自回归模型(SAR) :\(Y = \alpha + \rho WY + X\beta + \epsilon\) 空间杜宾模型(SDM) :\(Y = \alpha + \rho WY + X\beta + WX\beta + \epsilon\) 模型嵌套关系 :
SDM嵌套SAR和SEM模型
使用统计检验指导简化
SDM是最通用的(灵活的)模型
3.2 OLS残差的空间依赖性检验
零假设 :无空间依赖性两种变体 :
LM-lag:检验SAR模型
LM-error:检验SEM模型
当两者均显著时,使用稳健LM检验
library (lmtest)<- BIR74 ~ SID74 + NWBIR74 <- lm (form, data = nc) lm.RStests (ols_model, listw_contig, test = "all" )
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = form, data = nc)
test weights: listw_contig
RSerr = 25.91, df = 1, p-value = 3.577e-07
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = form, data = nc)
test weights: listw_contig
RSlag = 1.7312, df = 1, p-value = 0.1883
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = form, data = nc)
test weights: listw_contig
adjRSerr = 26.14, df = 1, p-value = 3.176e-07
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = form, data = nc)
test weights: listw_contig
adjRSlag = 1.9608, df = 1, p-value = 0.1614
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = form, data = nc)
test weights: listw_contig
SARMA = 27.871, df = 2, p-value = 8.869e-07
RSerr
无空间误差相关
SEM
RSlag
无空间滞后依赖
SAR
adjRSerr
在可能存在滞后时,仍无误差相关
SEM(稳健)
adjRSlag
在可能存在误差相关时,仍无滞后依赖
SAR(稳健)
SARMA
同时不存在误差和滞后相关
SAR / SEM 总检验
RSerr ✔️、RSlag ❌
空间依赖来自误差
SEM
RSerr ❌、RSlag ✔️
空间依赖来自因变量
SAR
两者都显著
结构不清晰
SDM
两者都不显著
无空间依赖
OLS
结论:Rao’s score 检验结果表明,OLS 模型残差中存在显著的空间相关,而空间滞后项并不显著,说明研究对象之间并不存在直接的结果变量相互影响或战略互动。相反,空间依赖更可能源于未被模型显式控制、但在空间上连续分布的背景性因素(如区域制度环境、社会经济结构或历史路径依赖),因此采用空间误差模型(SEM)更为合适。
从具体到一般:
拟合OLS
对残差进行LM检验
LM-lag 检测SAR
LM-error 检测SEM
若均显著,用R-LM检验
若确认存在空间依赖,拟合 SDM
使用 LR 检验比较 SDM 与 SAR/SEM
3.3 似然比检验(Likelihood Ratio Test)
比较嵌套模型 (e.g., SDM vs SAR)
检验统计量:\(LR = -2(\log L_{restricted} - \log L_{full})\)
服从卡方分布
拒绝原假设,则采用完整模型 (SDM)
一般到特殊:SDM → SAR / SEM
library (spatialreg)<- lagsarlm (form, data = nc, listw = listw_contig)<- errorsarlm (form, data = nc, listw = listw_contig)<- lagsarlm (form, data = nc, listw = listw_contig, type = "Durbin" )lrtest (sar_model, sdm_model)
Likelihood ratio test
Model 1: BIR74 ~ SID74 + NWBIR74
Model 2: BIR74 ~ SID74 + NWBIR74
#Df LogLik Df Chisq Pr(>Chisq)
1 5 -878.59
2 7 -869.13 2 18.911 7.827e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
lrtest (sem_model, sdm_model)
Likelihood ratio test
Model 1: BIR74 ~ SID74 + NWBIR74
Model 2: BIR74 ~ SID74 + NWBIR74
#Df LogLik Df Chisq Pr(>Chisq)
1 5 -869.41
2 7 -869.13 2 0.5554 0.7575
3.4 空间效应的正确解释:直接效应与间接效应
3.4.1 为什么不能直接解释回归系数?
在 SAR / SDM 中,(Y) 通过 (WY) 产生反馈回路:
$ (I - \rho W)^{-1} = I + \rho W + \rho^2 W^2 + \cdots $
3.4.2 三类效应
直接效应 :对本地单元的平均影响
间接效应 :对相邻单元的溢出影响
总效应 :两者之和
<- impacts (sdm_model, listw = listw_contig, R = 500 ) summary (impacts_sdm)
Impact measures (mixed, exact):
Direct Indirect Total
SID74 118.881175 22.2860019 141.167177
NWBIR74 1.914751 -0.3512729 1.563478
========================================================
Simulation results ( variance matrix):
Direct:
Iterations = 1:500
Thinning interval = 1
Number of chains = 1
Sample size per chain = 500
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
SID74 117.972 45.7793 2.04731 2.04731
NWBIR74 1.919 0.2494 0.01115 0.01115
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
SID74 28.557 85.708 120.679 150.123 204.720
NWBIR74 1.441 1.756 1.916 2.089 2.433
========================================================
Indirect:
Iterations = 1:500
Thinning interval = 1
Number of chains = 1
Sample size per chain = 500
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
SID74 18.4396 165.1651 7.38641 7.38641
NWBIR74 -0.3285 0.9082 0.04062 0.04062
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
SID74 -308.68 -88.5761 16.4430 126.730 339.758
NWBIR74 -2.09 -0.8843 -0.3296 0.181 1.477
========================================================
Total:
Iterations = 1:500
Thinning interval = 1
Number of chains = 1
Sample size per chain = 500
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
SID74 136.411 189.722 8.48464 8.48464
NWBIR74 1.591 1.036 0.04634 0.04634
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
SID74 -233.9912 14.2413 135.888 263.053 522.692
NWBIR74 -0.4603 0.9807 1.577 2.256 3.609
主要结论
SID74 对因变量具有显著而强烈的“本地直接效应”,但其空间溢出效应高度不稳定;NWBIR74 的影响主要体现在本地,空间溢出效应弱且不显著。
换句话说:
SID74:强本地影响 + 不确定的跨区外溢 NWBIR74:稳定的本地结构性影响 + 几乎没有可靠外溢
三类 impact 的“直观含义”
在 SDM / SAR 中:
Direct effect(直接效应) 自变量在某一区域变化,对该区域因变量的平均影响(含反馈回路)
Indirect effect(间接效应 / spillover) 自变量在某一区域变化,通过空间网络对其他区域因变量的平均影响
Total effect(总效应) Direct + Indirect
注意:这些 不是回归系数 ,而是通过 ((I - W)^{-1}) 展开的均衡效应 。
“点估计”(Impact measures 表)
Direct Indirect Total
SID74 118.88 22.29 141.17
NWBIR74 1.91 -0.35 1.561️⃣ SID74
直接效应 ≈ 119(很大) 间接效应 ≈ 22(正,但远小于直接效应) 总效应 ≈ 141
表面上看:SID74 对本地产生显著正向影响 ,并可能存在一定正向空间扩散。
2️⃣ NWBIR74
直接效应 ≈ 1.9(正) 间接效应 ≈ −0.35(负) 总效应 ≈ 1.56
表面上看:NWBIR74 的影响几乎完全来自本地 ,而且外溢效应方向不稳定。
“模拟分布和置信区间”
(1)Direct effects:结论最稳健
SID74(Direct)
均值 ≈ 119
95% CI:[31.6 , 210.8] 不包含 0
明确显著,且方向稳定
NWBIR74(Direct)
均值 ≈ 1.92
95% CI:[1.43 , 2.37] 不包含 0
同样显著,且非常稳定
结论 :
两个变量都对“本地结果”具有稳健影响。
(2)Indirect effects:不稳定,是解释重点
SID74(Indirect)
均值 ≈ 18
95% CI:[−276.8 , 322.0] 大幅跨越 0
这意味着:
溢出效应方向不确定
既可能正,也可能负
对 W 的结构和网络路径高度敏感
NWBIR74(Indirect)
均值 ≈ −0.34
95% CI:[−2.23 , 1.27] 同样跨越 0
完全不能认为存在稳定的空间溢出效应
(3)Total effects:被“间接效应不确定性”拖累
SID74(Total)
均值 ≈ 138
95% CI:[−223.9 , 503.5] 跨越 0
注意:
即使 Direct 显著,Total 也可能不显著 ——因为 Indirect 太不稳定
NWBIR74(Total)
均值 ≈ 1.58
95% CI:[−0.59 , 3.55] 边缘且不显著
统计结果解释
SID74 对本地因变量具有显著而稳健的正向影响,表明该因素主要通过地方层面的机制发挥作用。然而,其空间溢出效应在统计上并不稳定,说明该影响并未通过明确、系统性的跨区域传导路径扩散至相邻地区。
公共管理含义:
问题更像是 “地方性风险或需求”
而不是 “跨区政策模仿 / 战略相互依赖”
区域协同治理的必要性有限,精准地方干预更重要
NWBIR74 的影响主要体现在本地层面,其直接效应显著且稳定,而空间溢出效应不显著,表明该变量反映的是地方人口或社会结构特征,而非具有跨区域扩散特性的政策或行为。
公共管理含义:
属于 结构性、内生性强的地方特征
不适合期待“邻近地区联动效应”
空间杜宾模型的影响分解结果显示,SID74 与 NWBIR74 均对本地因变量产生显著且稳健的直接效应,而其空间溢出效应在统计上并不显著,且置信区间高度不稳定。该结果表明,相关影响主要通过地方层面的机制发挥作用,而未形成明确的跨区域扩散路径,这与前述 Rao’s score 检验中空间滞后效应不显著的结论相一致。
3.5 模型构建建议
始终测试空间依赖性
如有疑问,优先选择SDM模型,然后测试简化为SAR或SEM
当模型不明确时,使用稳健LM测试
谨慎解释SDM效应
3. 扩展:空间面板
双向固定效应 :时间与空间多种空间模型规格 :
参考文献:Cheng and Guo (2021); Han, Xiong, Cheng, and Guo (2022); Guo and Cheng (2018)
动态空间面板 :
因变量不仅在时间上相关,还在空间上相关
参考文献:Cheng, Guo, and Liu (2020)
空间Probit模型 :
空间多层次/层级模型 :
社交网络分析中的空间模型
推荐文献
Moraga, Paula. (2023). Spatial Statistics for Data Science: Theory and Practice with R . Chapman & Hall/CRC Data Science Series. ISBN 9781032633510
Pebesma, E.; Bivand, R. (2023). Spatial Data Science: With Applications in R (1st ed.). 314 pages. Chapman and Hall/CRC, Boca Raton. https://doi.org/10.1201/9780429459016
Anselin (1988). Spatial Econometrics: Methods and Models
LeSage & Pace (2009). Introduction to Spatial Econometrics
LeSage & Pace (2014). https://doi.org/10.3390/econometrics2040217
Bivand et al. (2013). Applied Spatial Data Analysis with R
Cheng & Guo (2021). https://doi.org/10.1080/03003930.2020.1794845
Guo & Cheng (2017). https://doi.org/10.52324/001c.8009
用到空间分析的公共管理论文
https://onlinelibrary.wiley.com/doi/abs/10.1111/pbaf.12160
https://www.tandfonline.com/doi/abs/10.1080/23276665.2022.2071305