----------------------------------------------------------------------
Your next step is to start H2O:
> h2o.init()
For H2O package documentation, ask for help:
> ??h2o
After starting H2O, you can use the Web UI at http://localhost:54321
For more information visit https://docs.h2o.ai
----------------------------------------------------------------------
Attaching package: 'h2o'
The following objects are masked from 'package:lubridate':
day, hour, month, week, year
The following objects are masked from 'package:stats':
cor, sd, var
The following objects are masked from 'package:base':
&&, %*%, %in%, ||, apply, as.factor, as.numeric, colnames,
colnames<-, ifelse, is.character, is.factor, is.numeric, log,
log10, log1p, log2, round, signif, trunc
Connection successful!
R is connected to the H2O cluster:
H2O cluster uptime: 8 days 5 hours
H2O cluster timezone: Asia/Shanghai
H2O data parsing timezone: UTC
H2O cluster version: 3.44.0.3
H2O cluster version age: 1 year, 11 months and 17 days
H2O cluster name: H2O_started_from_R_liangdan_ats696
H2O cluster total nodes: 1
H2O cluster total memory: 0.84 GB
H2O cluster total cores: 10
H2O cluster allowed cores: 10
H2O cluster healthy: TRUE
H2O Connection ip: localhost
H2O Connection port: 54321
H2O Connection proxy: NA
H2O Internal Security: FALSE
R Version: R version 4.4.2 (2024-10-31)
Warning in h2o.clusterInfo():
Your H2O cluster version is (1 year, 11 months and 17 days) old. There may be a newer version available.
Please download and install the latest version from: https://h2o-release.s3.amazonaws.com/h2o/latest_stable.html
The following object is masked from 'package:dplyr':
slice
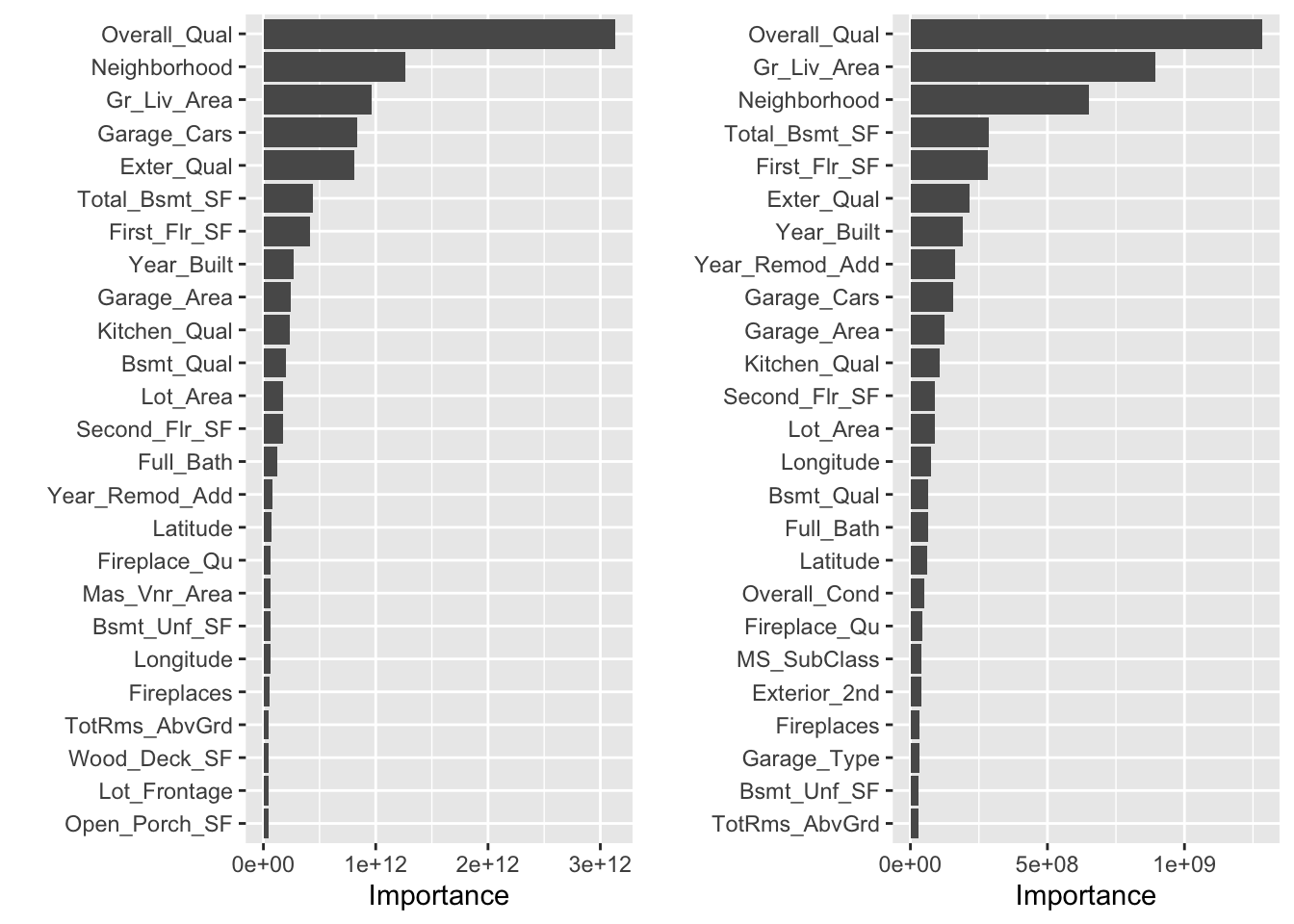
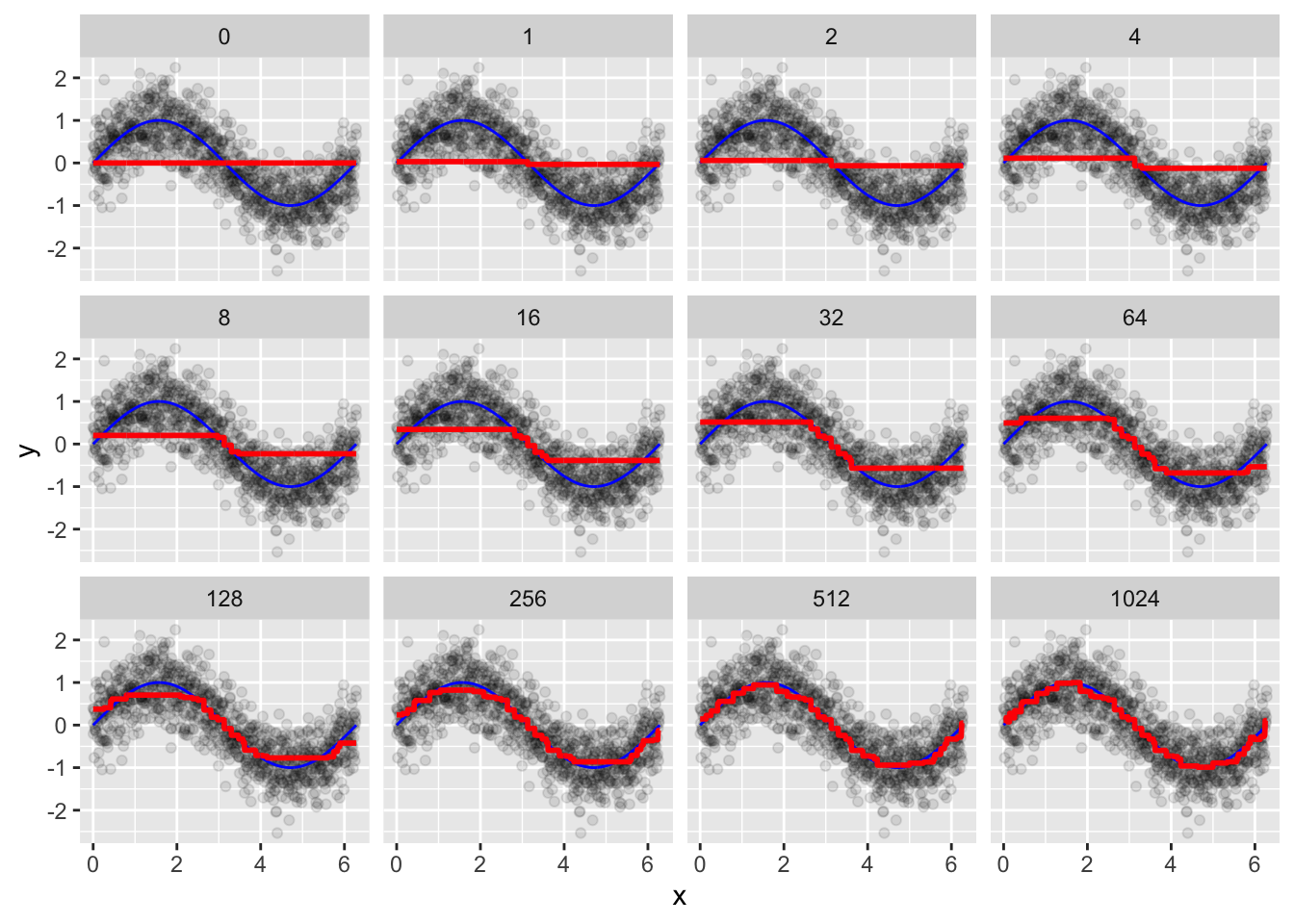
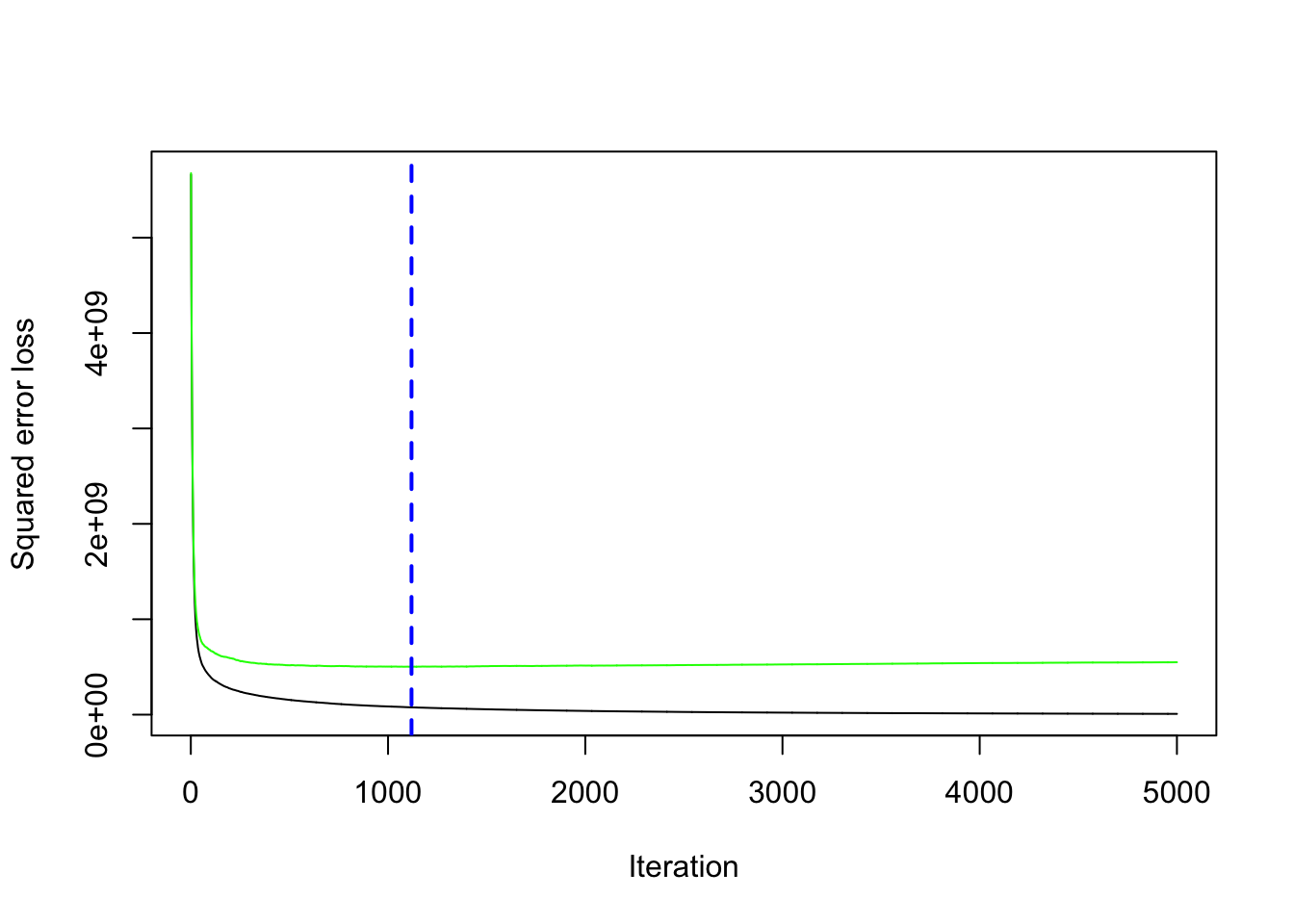
继续使用 ames_train 数据集,并复用前面的 h2o 环境设置。
h2o.init(max_mem_size ="10g")
Connection successful!
R is connected to the H2O cluster:
H2O cluster uptime: 8 days 5 hours
H2O cluster timezone: Asia/Shanghai
H2O data parsing timezone: UTC
H2O cluster version: 3.44.0.3
H2O cluster version age: 1 year, 11 months and 17 days
H2O cluster name: H2O_started_from_R_liangdan_ats696
H2O cluster total nodes: 1
H2O cluster total memory: 0.83 GB
H2O cluster total cores: 10
H2O cluster allowed cores: 10
H2O cluster healthy: TRUE
H2O Connection ip: localhost
H2O Connection port: 54321
H2O Connection proxy: NA
H2O Internal Security: FALSE
R Version: R version 4.4.2 (2024-10-31)
Warning in h2o.clusterInfo():
Your H2O cluster version is (1 year, 11 months and 17 days) old. There may be a newer version available.
Please download and install the latest version from: https://h2o-release.s3.amazonaws.com/h2o/latest_stable.html
flowchart LR
A[数据集] -->|训练| B[模型 1(弱学习器)]
B -->|测试| C[误差 1]
C -->|基于误差训练| D[模型 2(弱学习器)]
D -->|测试| E[误差 2]
E -->|基于误差训练| F[模型 3(弱学习器)]
F --> G[…… 多轮迭代 ……]
G --> H[综合所有子模型]
H --> I[最终预测结果]
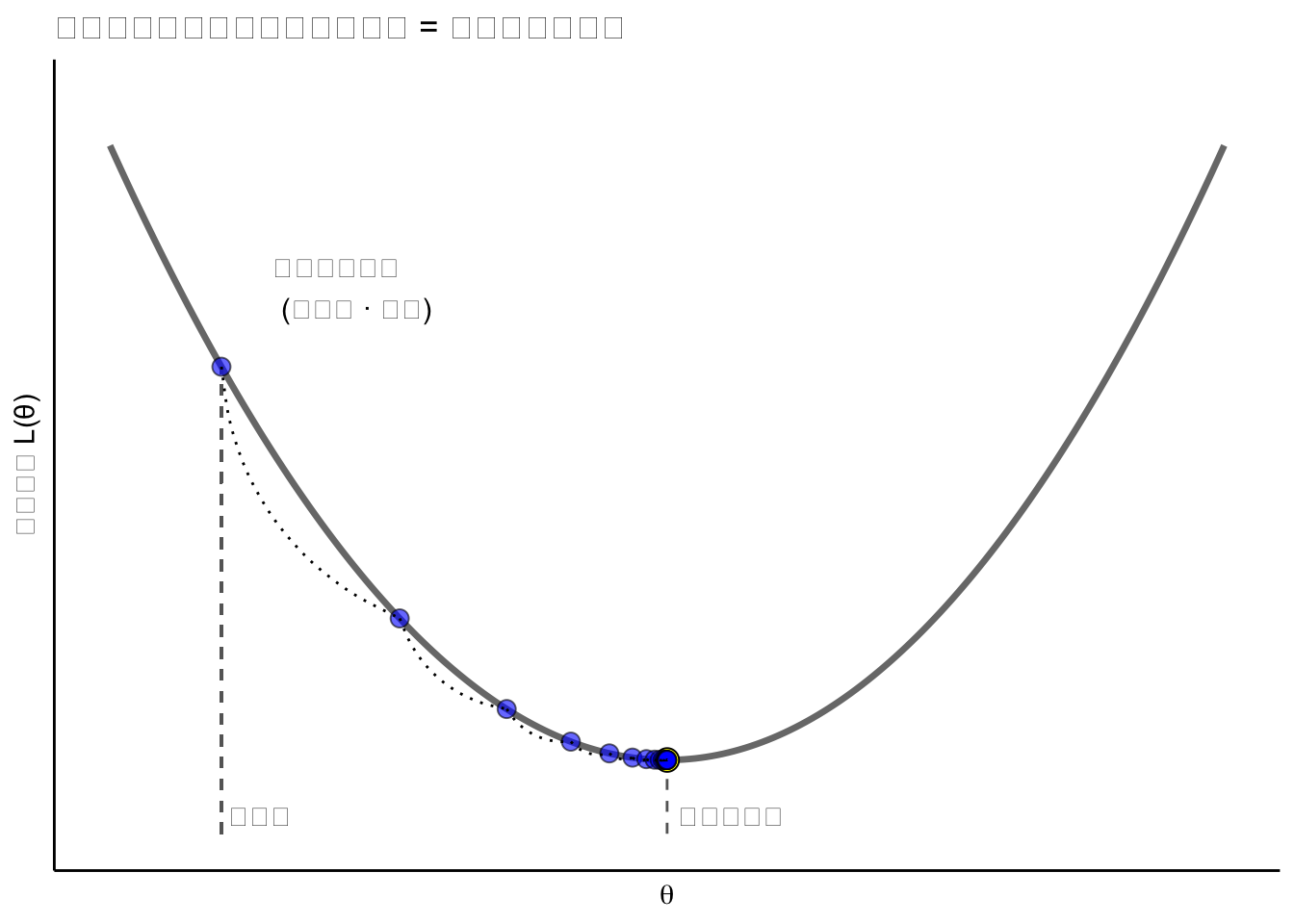
Warning in geom_segment(aes(x = theta0, xend = theta0, y = 0, yend = loss(theta0)), : All aesthetics have length 1, but the data has 201 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.